

This can seem like a rhetorical question: you should always invest in Data Quality! But we are still not investing enough: surveys show Data Quality issues are increasing in most organisations and on average, take up 34% of a Data Engineers time instead of them creating value by adding new features. This increases to 50% in large Data Platforms.
All these Data Quality issues add up, with bad Data Quality costing organisations on average $15mil a year.
Data Quality investment is also an investment in high-quality AI and ML, as you’ll likely get more accurate AI and ML results from improving Data Quality than changing your AI model and code.
Having Data Quality checks in place helps reduce “data downtime” for outages and fixes, which subsequently increases the overall reliability of the Data Platform. Highly reliable data leads to more trust in data and better-informed decision-making.
Better decision-making should increase profitability, productivity, and confidence of the whole organisation, which in turn usually leads to more investment in data and, as a result, going back to the start: Increasing the quality of data again.
All this creates a “Virtuous Cycle” of Data Quality, constantly improving your organisation:
If Data Quality decreases the opposite happens with a negative cycle.
Better Data Quality testing should also reduce the blast radius of the issue to a few Data Engineers rather than hundreds or thousands of users as more issues are being found earlier:
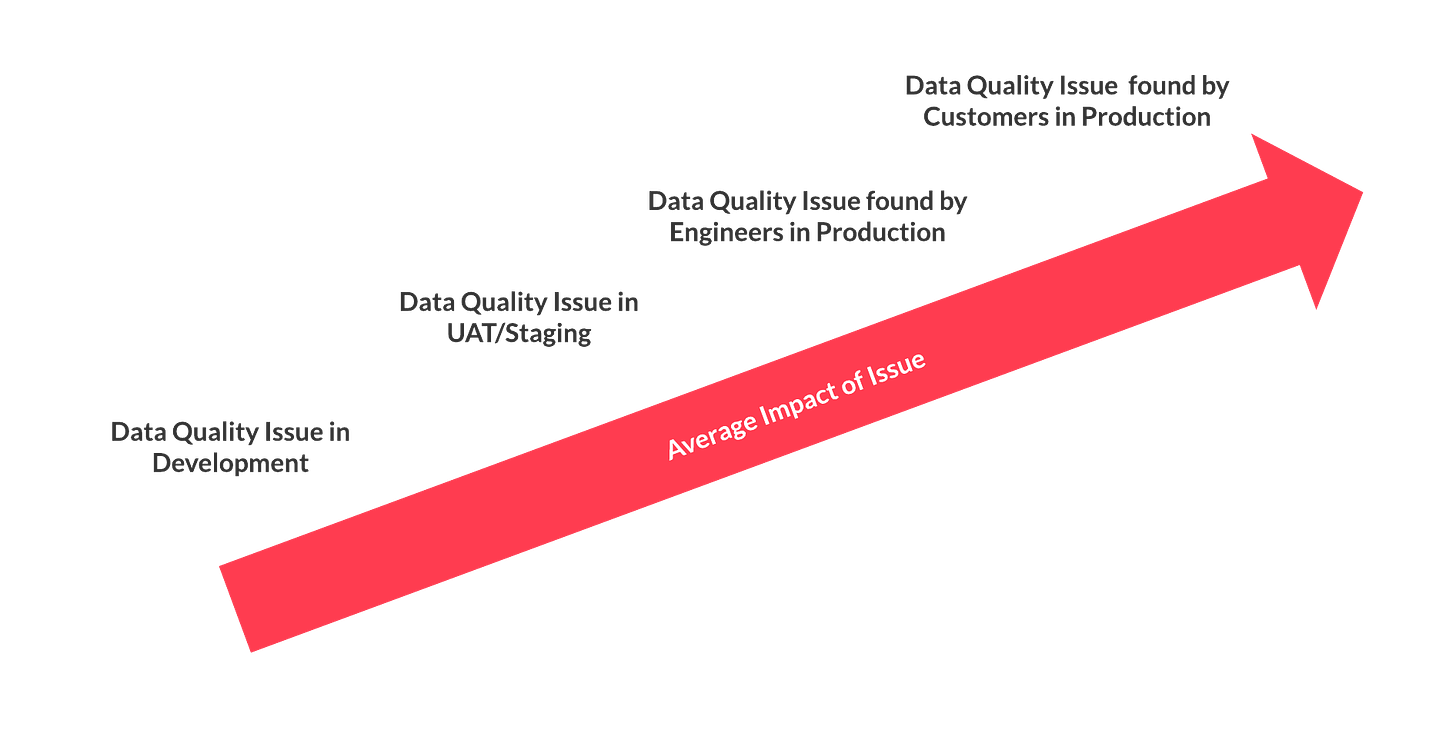
The fewer users impacted, the smaller the cost caused by the issue, which should again pay back any investment in Data Quality in large multiples.
Do I need a Data Quality Framework?
I know that setting out to build a framework for anything requires time, and you’ll have many competing concerns, so we understand if you feel reluctant to build one, especially if you are a small team with a limited budget.
But there comes a point where fighting lots of local battles with Data Quality becomes more inefficient than building out a framework to reduce Data Quality issues over the long term.
We’re not going to do a deep dive on Data Quality frameworks here, as they are often tied to wider Data Governance frameworks (you can download our guide here) We will say that whatever framework you use, make sure it’s cyclical so that it’s always improving and you are acting on any emerging issues in a timely manner.
How Do I Test for Data Quality?
Classically, Data Quality tests are a set of rules that test between the actual and desired state of data. The desired state may not be perfect, but ‘good enough’. What counts as ‘good enough‘ varies from dataset to dataset, which makes Data Quality more challenging.
What do we normally test in a dataset, though? The DAMA International’s Guide to the Data Management Body of Knowledge says there are six dimensions to Data Quality:
- Accuracy: does the date look how we expect it to?
- Completeness: are there any unexpected missing values?
- Uniqueness: no duplicates!
- Consistency: does a person’s data match in two different datasets?
- Timeliness: is the data out of date?
- Validity: does the data conform to an expected format? Think postcodes, emails, etc.
Tracking all these dimensions for every dataset at every stage of your pipeline is a lot of work, probably too much work. Therefore, a trade-off is often required to focus on areas where Data Quality will have the most impact on the business.
You also have to beware of false positives or minor issues being blown out of proportion, overwhelming your engineers with too many issues. It can help if you categorise your Data Quality issues by severity just like other software issues.
You also have to take into account the mental wellbeing aspect too: few Data Engineers and Analysts want to spend a large percentage of their time fixing Data Quality issues over a long period of time.
There is help, though, with software frameworks to help you write Data Quality testing:
Most of the above profile your data and setup recommended tests for you to use, saving you some time configuring them yourself.
But in reality, we see a lot of custom-made Data Quality testing, partly because Data Quality struggles for investment, so it is usually done in an organic, ad-hoc manner.
The above products work best in development and staging environments, so you can find issues before they enter production or use them as circuit breakers, to stop a Data Pipeline if the incoming or outgoing data is of poor quality.
It is also worth mentioning that you can use constraints in a Warehouse or Lakehouse schema, which have the benefits of not requiring another software library but are not as feature rich (you will likely have to setup your own notifications for alerting).
It is also important to inform your users of any Data Quality issues as soon as possible so they don’t waste time finding out for themselves or use data that is untrustworthy. This can be done through notifications and alerts, though we’ve also had a lot of success creating Data Quality dashboards that sit alongside existing reports and can be easily referred to by users.
Latest Concepts in Data Quality
There has been significant innovation in Data Quality in the last few years, so we present below the concepts to take your Data Quality process to the next level.
This will require more investment, but it will give you an edge over your competitors to make better informed decisions as you’ll have more trustworthy data. This investment should also pay back long term with less time wasted fixing Data Quality issues.
What is Data Reliability and do I Need it?
Data Reliability gives Data Quality more of a support focus, which makes sense as most Data Quality issues in production will be dealt with as a support issue to a Data Platform.
Data Reliability takes a lot of its thinking from Site Reliability Engineering (SRE), which treats support as more of a engineering problem, where you examine your past and current support tickets and look to decrease them with engineering or better processes.
With Data Reliability, you would look to get a baseline of Data Quality issues per week or month and then look at ways to reduce them and monitor to see if the changes have reduced the number of issues and/or reduced the amount of time spent on issues.
The changes to improve Data Reliability can be technology-based:
- New or updated tooling
- Better automation of when a pipeline fails or automated actions to respond to a data issue
Or the changes can be process-oriented:
- Writing better documentation to avoid common issues
- Incident playbooks so the whole team can more quickly respond to a issue in an consistent way.
You can rather cynically say Data Reliability is just Data Quality with a feedback loop and a time series graph, but it is there to make sure you avoid short term thinking about Data Quality and instead consider long term improvements that will make your data platform more efficient and trustworthy.
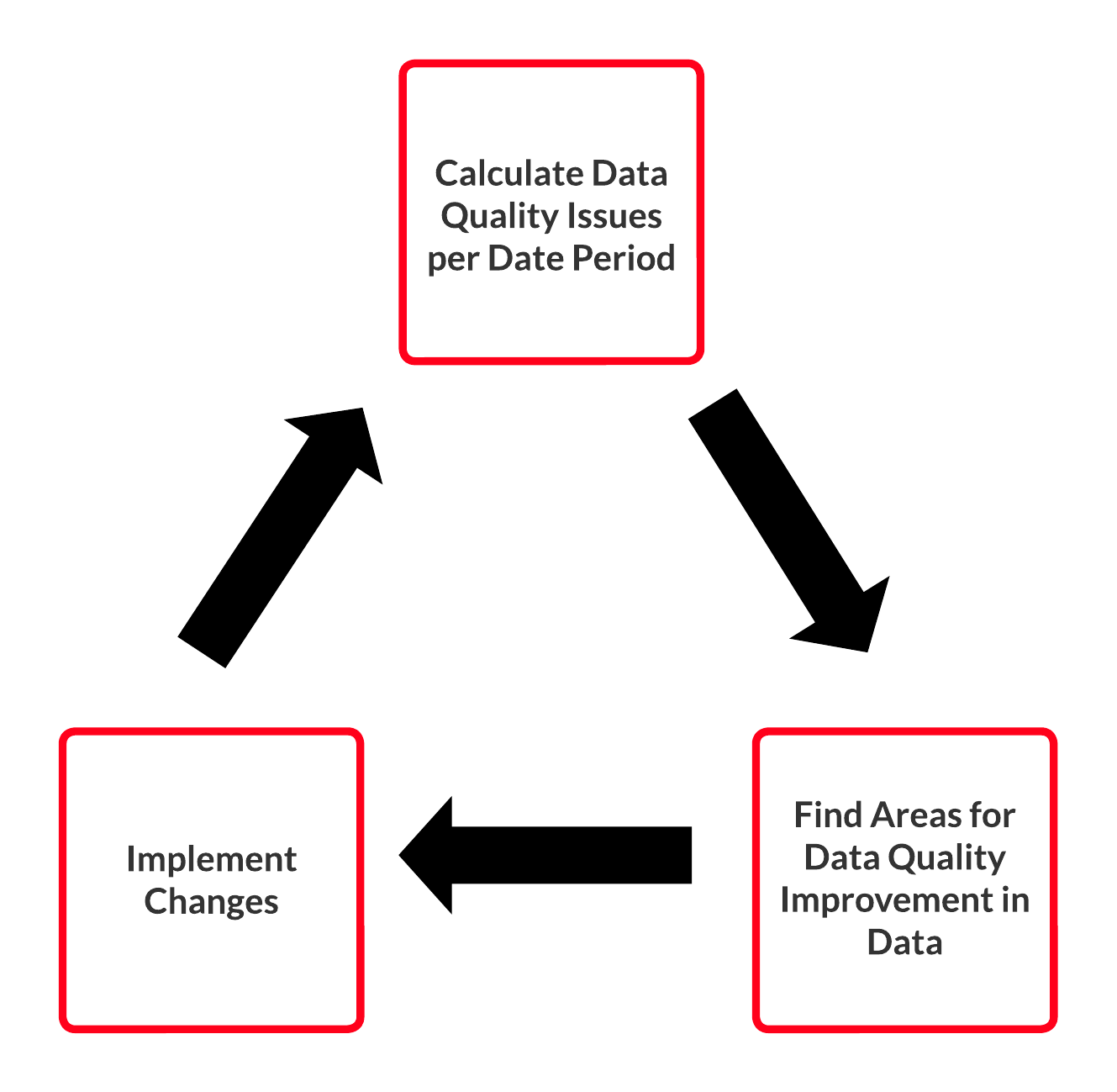
Data Reliability Cycle
You may also set targets such as “99.9% of data will refresh on time” or “A maximum of 33% of engineer time should be spent on support issues“ as well. As mentioned before, it can be impossible to achieve perfect Data Quality, so aiming for a reasonable target instead can avoid engineer burnout.
What is Data Observability and do I Need it?
Data Observability is about gaining a Data Platform or organisation-wide understanding of your Data Quality.
It arguably goes beyond Data Quality by adding metadata features normally found in a Data Catalog: cataloguing schemas of datasets and data lineage. These features allow you to more quickly find a Data Quality issue by tracing the lineage of the issue and also you gain the ability to see how much Data Quality is impacting your organisation.
Data Observability software can often also come with Machine Learning (ML) algorithms to detect anomalies in data, so you can be warned about issues you haven’t even thought of yet.
We’ve seen products either extend a Data Quality framework with Data Catalog features such as Monte Carlo and Big Eye. Or existing Data Catalogs add Data Quality functionality, such as Datahub, which imports Data Quality tests created by Great Expectations and dbt tests. Both Soda and Monte Carlo have integration with the Data Catalog Alation.
What are Data Contracts and do I Need Them?
Data Contracts make a contract between a data producer and a data consumer, so the consumer knows what data to expect from the producer.
While you can replicate some of a Data Contract’s benefits by tracking the schema of the data produced, a Data Contract is meant to go beyond that by giving you a full suite of metadata about the data:
- The data’s schema.
- How the data is calculated.
- Who owns the data?
- What is the data lineage?
- How to access the data.
- What is the data’s expected quality, availability, etc.
- Plus anything else that is relevant to the data.
You may think Data Contracts are redundant if you have a well-maintained Data Catalog, as they capture similar information, but Data Contracts are designed to be checked during every run of a Data Pipeline and have some action in the pipeline if the Data Contract is broken:
- Stop the pipeline with a circuit breaker.
- Alerting.
- Moving data that doesn’t meet the contract to a manual checking table.
For an example, Paypal has open-sourced their Data Contract template.

https://github.com/paypal/data-contract-template
This should create more positive collaboration between data producers and consumers because they have a collective agreement of what the data should look like. It is not uncommon to have a poor working relationship where a producer makes changes without telling consumers or consumers accessing data in way not recommended by the producer.
One issue with Data Contracts is that they are a new concept, so require more work to implement at present, though that will likely change in the near future as more companies adopt them.
Most of the examples of Data Contracts we’ve seen so far use Apache Flink and the Kafka Schema Registry, so assume you are using streaming, though there are some examples that use batch processing.
Data Governance and Data Quality
Good Data Governance can also improve quality of data. It is important to know where data is coming from, who owns it, for what purpose data is being transformed, and finally, what is the impact of poor availability and data quality: all helped by having Data Governance properly implemented.
Some of the above concepts (Data Contracts and Data Observability) can also improve Data Governance, so investing in Data Quality can also be an investment in good Governance too.
How Does This All Fit Together?
The diagram below is one example of how it all fits together:
- Any code changes are tested in development and/or test environments with Data Quality Tests to check that any changes won’t have a negative impact on Data Quality.
- Source Data at the start of the data pipeline is checked to see if the Data Contract is held; if not, a circuit breaker may kick in, stopping the data pipeline early to avoid processing unsuitable data.
- Data Quality tests are also run in production, which can feel like duplication from testing in development, but there may be changes caused by moving to a production environment (different data, etc.).
- Data is collected for observability checks by Data Observability software, looking for any anomalous data: a department budget that goes from £10k to £1mil or 10x increase in rows for a table, for example. This can replace a lot of tests, but not all of them.
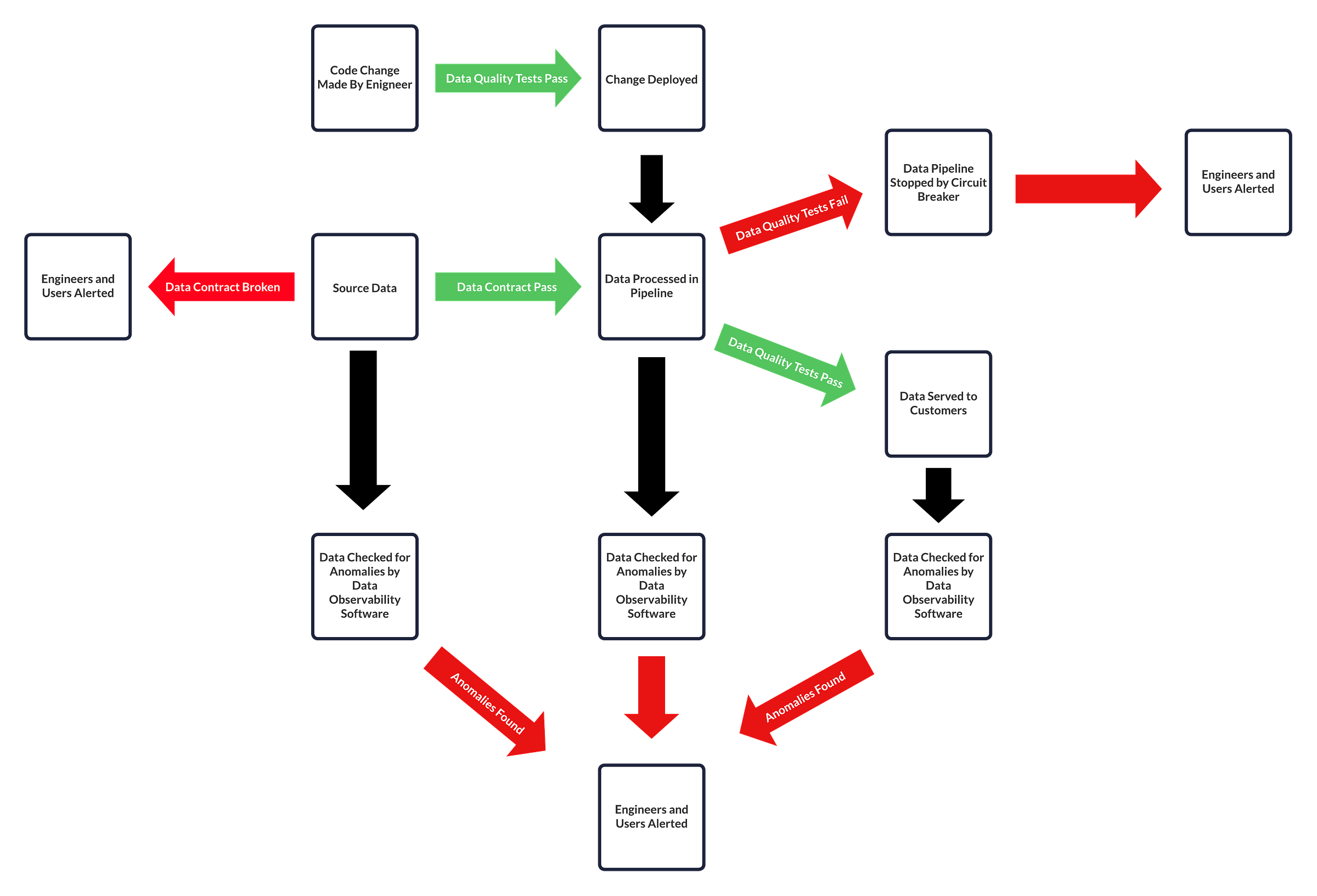
You’ll also be collecting Data Quality metadata to improve your Data Reliability.
Making all this work together seamlessly isn’t cheap and will take time, but as mentioned, poor Data Quality will also cost an organisation a lot of money. So we recommend tackling this in an agile manner by improving Data Quality in small increments, one change at a time, starting where it will have the most impact.
Summary
Data Quality is a difficult subject to tackle, due to it being a slightly different problem in every organisation and never “perfect”. That said, there are lots of options to help improve the quality of your data, so you should be able to get to “good enough“ if you give Data Quality enough priority and forethought.
Jake Watson is a Principal Engineer at Oakland

