

Most medium to large companies have a sizable Microsoft SharePoint space, containing thousands, if not millions of data files – but do you know what exactly is in them? In this post, we’ll lay out three core elements for gaining control of your SharePoint data, below, and most importantly why.
- Outlining the strategy and tooling to map SharePoint Data into a Data Governance strategy
- How to ingest SharePoint tabular data like CSV and Excel files into a Data Lake and/or Data Warehouse
- How to start classifying your SharePoint data for Data Quality, Master Data Management, and sensitive data exposure.
(Note the following applies mostly to Office 365 version of SharePoint, SharePoint Online, not the on-premises versions of SharePoint that uses different APIs, though would follow the same broad strategy.)
Building an Initial Assessment of SharePoint Structure and Data
To better regulate this space, you first need to assess your SharePoint Structure and data before planning any changes or policy decisions. In essence, you need to know what the current issues are and how much work it’s going to take to reach certain standards of process and data quality.
To be able to crawl a SharePoint site, and understand its contents, you need two things – authentication via linked Azure Active Directory and the Microsoft Graph API, to enable bulk download of data and automate custom actions. Being a web REST API, it can be called through most programming languages and special API debuggers like Postman.
A SharePoint site can be crawled for files by first finding all the base folders, known in the Graph API as Drives, and then searching through all or some of the base folders. Finding all the files does require a bit of work as there is no “get all folders and files in drive” API call we can make – but you can write some code of medium complexity to find all the folders, sub folders and files of a SharePoint Base folder.
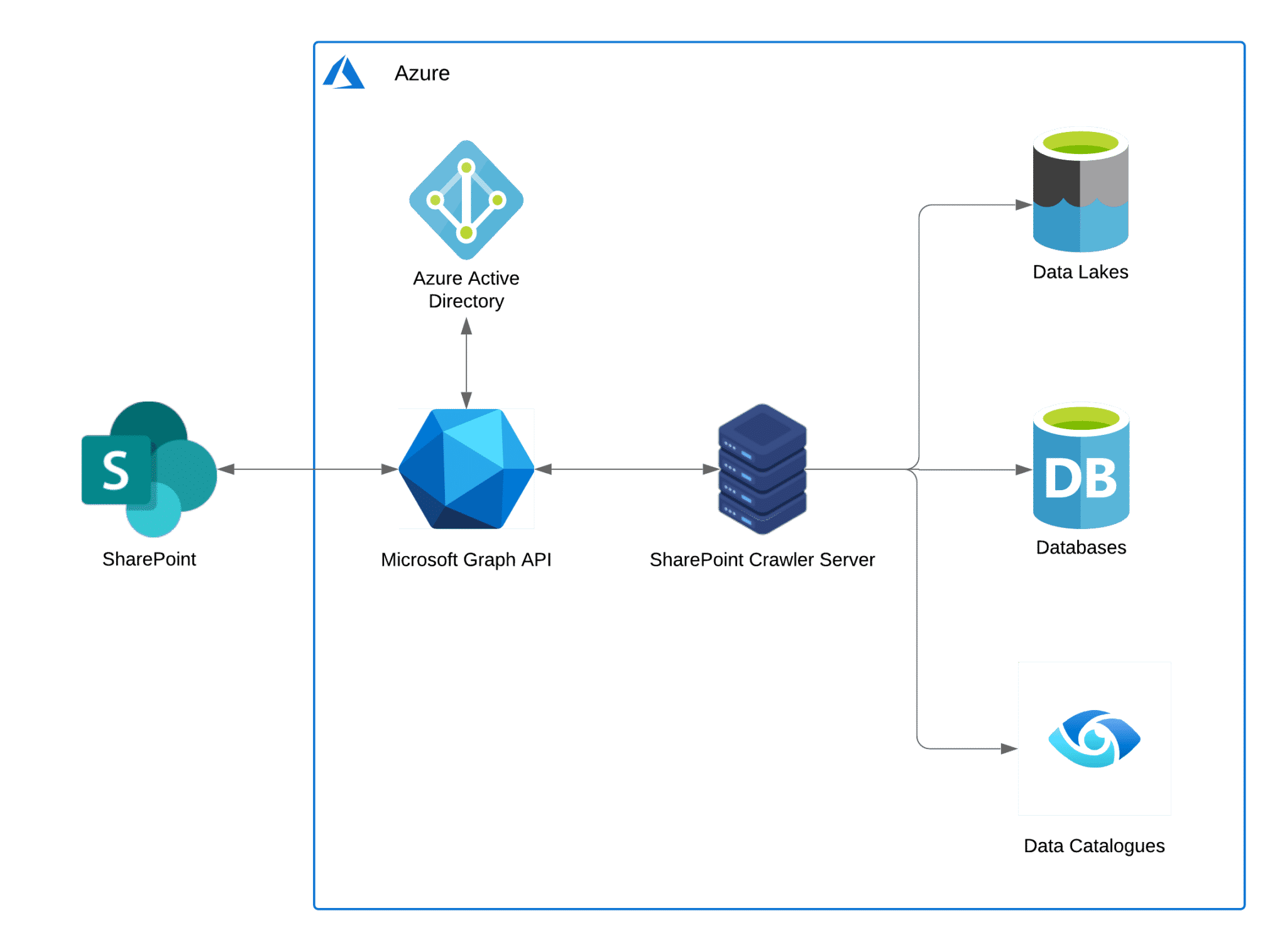
Example architecture – note while Azure Active Directory is a requirement, the Graph API can communicate with servers in other cloud environments such AWS, GCP or other locations, if allowed to.
Ingest tabular data into a Cloud Data Lake and/or Data Warehouse
Because every file has a unique URL (web address), that can be retrieved when it is scanned by the Graph API, we can now download all files in SharePoint via the URL into the cloud and convert it to a Data Lake file or Data Warehouse table (there is also more advanced strategies of combining multiple files into one table).
There should be a large caveat applied to this – it’s likely some or even most Excel sheets cannot be ingested into a Data Warehouse if it does not match a pre-determined template or is not machine-readable (examples below on what is machine-readable or not).
This isn’t the end of the road for unreadable files – we can use the SharePoint Crawler we built in the previous step to flag which files are readable or not, with the results helping to start a process to update the data so that it is readable by databases and software programs.
Also, it is possible to read data of other types of files – Word Documents and PDFs, etc. – however, they should match a robust template so a program can read their data reliably or use a Machine Learning Algorithm, however, this approach may give inexact results.
Classifying and Mastering your SharePoint Data
Once your data is in a cloud data source, it can be an easy process to assess your data. Data Governance tools such as Azure Purview can be used to classify your data and detect Personally identifiable information (PII) information or use database tools such as SQL Server’s sensitive data detection tools.
Once classified, you can begin to shape your data mastery, where you choose one “true” version of an object such as Customer, Contract, Project, Product, etc, for other sources to compare against.
However, this can become rather complicated if you have multiple sources of the same data. As such, it’s recommended to use specialist Master Data Management (MDM) software – these often require a Data Warehouse / Data Lake sources, so SharePoint data will benefit from ingestion into the cloud as mentioned above.
But Why?
So why go to such lengths to classify and master your SharePoint data? Mainly due to the consequences of using incorrect/outdated data or unnecessarily exposing sensitive data, some of which are listed below:
- Fines for breaching GDPR
- Fines from financial authorities for incorrect financial information.
- Loss of reputation and future sales for data leaks and incorrect data
- How to improve your SharePoint Site
- Saving rework of data by finding incorrect data, out-of-date data, and removing duplicates.
Aside from this more negative viewpoint, better management of your SharePoint data can also drive more positive impacts, such as the ability to perform additional analyses and grasp a better understanding of your organisation.
As you’d expect, completing this work can be rather difficult, due to the potential amount of data and number of nested folders in a companies’ SharePoint space. However, it can be made easier through automated tooling, such as the scanner mentioned earlier, and with some guidance from those who’ve been there before. We at Oakland have decades of experience in quality improvement from various angles, including people, processes and technology, should you like additional resources in this area.